
En el artículo anterior se abordaron los requerimientos funcionales de la herramienta spampot, un honeypot enfocado en capturar, analizar y ayudar a identificar el origen o destino de los correos electrónicos no desados. En esta segunda parte se mostrarán las formas de ejecución de spampot.
Funcionamiento y estructura
La herramienta fue desarrollada para interactuar con equipos que envíen correo malicioso en Internet por medio de una arquitectura cliente-servidor, es decir, los clientes (remitentes de correo malicioso) se conectan al servidor (spampot) por medio de un socket, el cual se encuentra a la espera de nuevas conexiones en el puerto 25 (reservado para SMTP). Por cada conexión de un cliente, el servidor crea un hilo para atender dicha petición, la cual consistirá en el envío de un correo electrónico malicioso y el servidor simulará el envío del correo a su destino. Para este caso, los correos no son enviados pero sí analizados en busca de patrones que puedan dar un indicio sobre alguna actividad maliciosa, ya sea recurrente o que se detecte por primera vez en la red en donde se ejecute la herramienta.
Spampot está estructurada para analizar el correo electrónico recibido en cuatro fases:
La primera es la fase de red y recolección en la cual se llevan a cabo todas las funciones para preparar al servidor: verificar que se pueda poner el puerto 25 a la escucha en TCP; procesar todas las variables para los registros del servidor, tales como el directorio de trabajo, el directorio para guardar los correos electrónicos, la ubicación de la bitácora de ejecución del programa y algunos parámetros extra para el análisis de correos; obtener la información de red de los clientes conectados es decir, la dirección IP y el puerto origen, y los comandos para la interacción por medio de SMTP.
La segunda fase se ejecuta cuando la conexión con el cliente se ha cerrado y consiste en leer el archivo con la información del correo electrónico y buscar dentro de éste patrones de cadenas de caracteres que hagan referencia a campos específicos de un correo electrónico. Debido a que la información se recolecta en un archivo de texto plano, al emplear expresiones regulares con el lenguaje de programación Perl, la búsqueda de estos patrones en el archivo de texto se lleva a cabo de forma rápida y sencilla.
Dentro de los patrones al buscar se encuentran las siguientes categorías:
- Direcciones de correo electrónico origen y destino con el formato básico usuario@dominio.com y sus variantes
- Asunto del correo a través de la palabra Subject
- Nombres de usuario obtenidos de las direcciones de correo electrónico
- Direcciones IP (versión 4) origen y destino y direcciones IP en los encabezados y cuerpo del correo
- Las URL que representan la dirección y ubicación correcta para acceder a un recurso en Internet
- Patrones predefinidos por el usuario, para encontrar información más específica
Una vez que se han encontrado estos patrones dentro del archivo de correo electrónico todos y cada uno de ellos son almacenados en un tipo de dato de Perl llamado arreglo asociativo hash, que es un conjunto de datos conformado de una llave y un valor. De esta manera es muy fácil almacenar información que se requiera cuantificar, expresar un número o agrupar datos dentro de otros (anidamiento).
En la Figura 1 se muestra un archivo de correo electrónico capturado por la herramienta el 7 de septiembre de 2014 y contiene la siguiente información (los caracteres ‘#’ o ‘X’ ocultan información sensible que pudiera comprometer al sensor o a los usuarios de correo electrónico involucrados):

Figura 1. Muestra de correo electrónico capturado el 7/9/2014
De este archivo de correo electrónico se obtuvo la dirección IP que se conectó al sensor y desde donde se envió toda la información. La segunda fase obtuvo los valores mostrados en la figura 2:

Figura 2. Registro generado por la segunda fase de ejecución
En la tercera fase de la herramienta se llevan a cabo dos acciones. La primera consiste en utilizar las URL encontradas para descargar posibles archivos maliciosos o relacionarlos con actividad maliciosa que intenta propagarse a través de correos electrónicos. La segunda es decodificar los archivos adjuntos del correo electrónico, los cuales viajan en una cadena de caracteres codificados en Base64.
Al finalizar la tercera fase, todos los archivos descargados o decodificados son sometidos a una verificación de integridad utilizando un algoritmo digestivo llamado MD5. Gracias a este algoritmo, se podrán comparar las cadenas MD5 obtenidas de los archivos contra alguna base de datos de firmas de archivos maliciosos en Internet, como Virus Total[1].
La cuarta y última fase consiste en obtener toda la información de los arreglos asociativos que contienen los patrones buscados para procesarla y enviarla a una base de datos; ésta es el lugar lógico donde se guarda toda la información de las direcciones IP de los clientes y de los sensores, los patrones encontrados, las URL y los MD5 de los archivos que se relacionan con el correo electrónico capturado. Una vez insertada en la base de datos toda la información recolectada, se cierra la conexión con la base de datos y el hilo termina, liberando la memoria y archivos utilizados para atender una nueva conexión.
Estructura de la base de datos
Los datos almacenados en la base de datos se guardan por medio de eventos, es decir, cada conexión al servidor (sin importar si es la misma dirección IP origen) se considera un evento. Cada evento puede contener uno o varios correos electrónicos recibidos, ya que de acuerdo al protocolo SMTP, se pueden enviar desde uno hasta varios correos por conexión a un servidor. Por cada evento se genera un identificador de evento (id_event), se obtiene la fecha y hora en que se registra la conexión, y se registra la dirección IP del cliente, la dirección IP del sensor (para identificar cada sensor en caso de contar con más de uno) y los puertos origen y destino. Toda esta información se almacena en una tabla llamada Events, la cual tiene como llave primaria al campo id_event. Los patrones encontrados en cada evento se almacenan en seis tablas dentro de la base de datos:
- Binaries: con una llave primaria llamada id_binary, el campo md5_list y la llave foránea id_event.
- Domains: con una llave primaria llamada id_domain, los campos id_domain, source_domain_list, destination_domain_list y llave foránea id_event.
- IPs: con una llave primaria llamada id_ip, el campo ip_list y la llave foránea id_event.
- Subjects: con una llave primaria llamada id_subject y llave foránea id_event.
- URLs: con una llave primaria llamada id_url y llave foránea id_event.
- Usernames: con una llave primaria llamada id_username y llave foránea id_event.
Todas las tablas contienen una llave primaria y, a excepción de la tabla de eventos, una llave foránea. Esta llave foránea hace referencia a la llave primaria de la tabla de eventos para relacionar los patrones encontrados con un evento determinado.
El formato utilizado para almacenar la información dentro de la base de datos es:
patrón1|no. veces,patrón2|no. veces… patrónN|no.veces
Éste provee una gran rapidez para consultar la información almacenada utilizando expresiones regulares y técnicas de búsqueda por separadores de campos. Basta con realizar la consulta a la base de datos en la tabla deseada y seleccionar cualquier campo que termine con la palabra list, a continuación se deben separar los campos primero por comas (,) y después por un pipe (|) para obtener la llave y el valor del arreglo asociativo.
Ejecución de la herramienta
Para ejecutar la herramienta, todos los módulos de CPAN deben estar correctamente instalados y la base de datos configurada correctamente. La configuración de la base de datos se debe hacer directamente en el servidor de base de datos y consiste en crear una base de datos denominada spampot y un usuario llamado spampot, el cual deberá tener todos los privilegios sobre la base de datos spampot. Todos los comandos de configuración de la base de datos se muestran en la Figura 3.
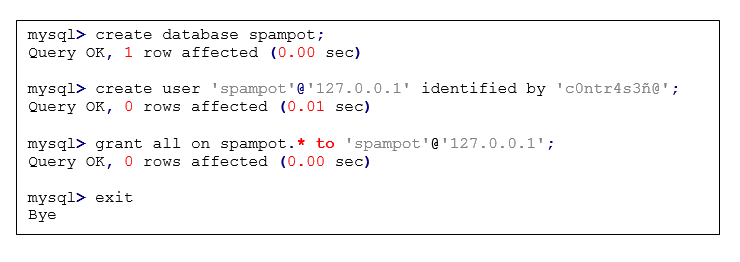
Figura 3. Configuración del usuario de la base de datos
El puerto de red en el que la herramienta se ejecuta es el 25, correspondiente a STMP de acuerdo a la IANA. Todos los puertos menores al 1024 se llaman puertos reservados y, por lo tanto, requieren privilegios de administración para asignar una aplicación en éstos. El comando de ejecución de la herramienta y los resultados de la misma al recibir y analizar un correo electrónico se encuentran en la Figura 4.

Figura 4. Ejecución de la herramienta
En la ejecución mostrada en la sección anterior se observa una salida con la opción Debug habilitada con el valor 1, por lo que se identifican en pantalla varios mensajes que están clasificados en cinco códigos de color, los cuales corresponden a:

En la Figura 5 se muestra la bitácora de la herramienta correspondiente a la ejecución anterior, la cual únicamente contiene los mensajes de la herramienta y las funciones como se fue llevando a cabo la ejecución.
El formato de la bitácora es el siguiente:
[Marca de tiempo]-[Tipo de mensaje]-[Seguimiento]-[Mensaje de la bitácora]
La marca de tiempo tiene el formato AAAA-MM-DDTHH:MM:SS.
El tipo de mensaje utiliza cuatro etiquetas sobre la ejecución:
- FATAL_ERROR: Error fatal y termina la ejecución inmediatamente.
- ERROR: Error genérico que requiere de una corrección por parte del usuario.
- WARNING: Advertencia sobre un posible fallo pero sin terminar la ejecución.
- INFO: Informe de la ejecución y las acciones realizadas.
- DEBUG: Muestra información más detallada y ayudar a detectar errores.
El seguimiento indica las funciones que han sido ejecutadas en el momento en que se escribe un mensaje en la bitácora; es un formato separado por el símbolo ‘|’. Por último, el mensaje de la bitácora indica la acción que se está realizando.

Figura 5. Bitácora de ejecución
Resultados
Con el objeto de verificar el correcto funcionamiento de la herramienta, se llevó a cabo una fase de pruebas para descartar errores de ejecución, fallos en la recepción y envío de los comandos y la información, así como el análisis de la información que fue capturada.
Estas pruebas fueron realizadas utilizando servicios de verificación en línea, herramientas de uso abierto y la ejecución de la herramienta directamente en el entorno de investigación, mencionado en la primera parte de este artículo. Los servicios en línea utilizados para las pruebas de la herramienta son:
- MailRadar (http://www.mailradar.com/openrelay/): Es un servicio que realiza 20 pruebas a través del envío de varios correos electrónicos con diferentes remitentes y destinatarios analizando las respuestas del servidor de correo para determinar la configuración del servidor.
- MXToolBox (http://mxtoolbox.com/diagnostic.aspx): Servicio en línea que realiza una verificación del servidor SMTP y además corrobora que el nombre de dominio asociado al servidor, corresponda con el mensaje de inicio e identificación del servicio de correo que se ejecuta.
Las herramientas de uso abierto utilizadas para probar la herramienta son:
- SWAKS (http://www.jetmore.org/john/code/swaks/): Denominada la navaja suiza para SMTP (Swiss Army Knife for SMTP) es una herramienta con varias opciones de ejecución para verificar el correcto funcionamiento de servidores de correo electrónico.
- relaycheck.pl (http://arpa.org/relaycheck.pl): Es un programa escrito en el lenguaje de programación Perl para realizar una verificación rápida de un servidor de correo electrónico mal configurado.
Dentro del entorno de investigación se recibe una gran cantidad de tráfico de Internet hacia las direcciones IP no asignadas de la red corporativa, por lo que todo ese tráfico originado por otras aplicaciones o usuarios en Internet se considera potencialmente malicioso. Bajo este esquema se reciben múltiples peticiones de diferentes aplicaciones por lo que, con este entorno, también se verifica la capacidad de respuesta de la herramienta ante grandes cantidades de tráfico.
Actualmente la herramienta se encuentra en la versión 1.0. El código fuente de la misma versión se encuentra disponible y gratuito para su uso y distribución en el sitio GitHub. En la siguiente URL se accede directamente a la herramienta en el siguiente enlace: https://github.com/miguelraulb/spamhat. Dentro de la misma se encuentran las instrucciones y requisitos para ejecutar la herramienta, además se incluye un archivo instalador (installer.sh) para automatizar todo el proceso de instalación incluyendo las dependencias necesarias.
Conclusiones
Con el desarrollo y la implementación de esta herramienta se logró una gran visibilidad en la red para detectar nuevas amenazas y ataques debidos a la recepción masiva de correo electrónico no deseado en una red corporativa. Además, en conjunto con el análisis de patrones, se pudieron determinar las direcciones de correo electrónico, direcciones IP y nombres de dominio más utilizados dentro de estos ataques. Finalmente con el análisis del contenido de los archivos adjuntos y de las URL contenidos en el cuerpo del correo electrónico, se lograron detectar sitios con contenido malicioso, información fraudulenta o redirecciones a otros sitios maliciosos.
Debido a la forma en cómo se almacena la información dentro de la base de datos, se puede obtener un histórico de la actividad recolectada y clasificarla por día, mes y año. Gracias a estos históricos la información de los ataques recibidos es más fácil de revisar, entender y de comprender.

Figura 6. Top 20 países atacantes detectados en el entorno de investigación
Si quieres saber más consulta:
- Spampot para la captura de correo electrónico no deseado
- Evita el correo basura: antispam
- Día de limpieza
[1] Virus Total es un sitio en Internet que permite analizar archivos, obtener el MD5 del archivo y compararlo con una lista de antivirus comerciales para así saber si el antivirus detecta la pieza maliciosa. También permite buscar directamente una cadena MD5 o una URL y realizar el mismo análisis que con un archivo malicioso.


